Making data science accessible – Text Mining

What is Text Mining?
Text Mining is a general catch-all for a range of techniques for extracting information from text strings. Being able to extract, clean and summarize text data is a key ability for any Data Scientist. The following blog aims to highlight some of the process steps I use to clean text data as well as some summarization methods.
Initial cleaning
To illustrate some of the approaches to text mining I am going to use the full text of 1984 by George Orwell. This data was extracted from msxnet.org/orwell with analysis carried out in R. There are some straight-forward steps we can take to start to clean the data as illustrated below. If we are focusing on the actual words we may want to remove numbers, punctuation and additional white space.

Stop Words
Once we have standardized the text we can start to hone in on key words. One approach to this is to remove ‘stop words’. Stop words are specific to a language and are usually the most frequently occurring words in the language such as ‘the’, ‘is’, ‘at’ and ‘on’. I have used the inbuilt list of stop words with the R package. This leads to potential issues if you are mining text about ‘Take That’ however it does reduce the amount of text and allows you to start to pull out themes on the less frequent words.
Lemmatization or Stemming
Both lemmatization and stemming are approaches to try and standardize the remaining text. Stemming can be quite a crude approach following a series of rules (for example removing a trailing ‘s’ so ‘cars’ would become ‘car’). By having these basic rules in place stemming can be applied quickly to data. Lemmatization involves a more complex approach (in essence a large look-up to convert any word into its derivative). The below example applies stemming to our text. Interestingly enough this approach starts to look like 1984’s Newspeak!

Analysis
Now you have cleaned, standardized text data there are all kinds of analyses you can carry out:
– Word clouds give a quick overview of frequently appearing words and may allow comparisons across different text sources. Top words in 1984 are ‘winston’, ‘said’, ‘even’ and ‘thought’.

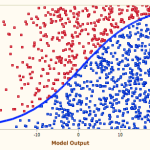
– Basic frequency analysis over time can pick out trends or help identify new themes. For example: this chart picks out chapters more focused on Winston versus the Party.

– Clustering of words can help pull out themes – ironically clustering ‘winston’ with ‘party’ (probably against his will).

Examples where we’ve used Text Mining at Capital One:
Reason for call
Whenever our agents speak to our customers they capture important information about the call through their notes. We have been able to read-in, process and analyze these notes to help classify the reason for the call. This has been hugely helpful in understanding what our customers find important to help shape future development for our mobile app or website to make their lives easier and minimize the need to call in.
Compliance investigation
By being able to identify key words in the notes our agents make we are able to quickly identify calls that meet specific criteria. This makes it easier to review calls to ensure our agents continue to be compliant with laws and regulations rather than manually sift through cases. This helps save time and ensures we remain focused on running a well-managed business.
When would I use Text Mining?
As with any technique related to data science Text Mining is one of many approaches you could take to solve a business problem using large amounts of data. Obviously the technique should be applied where you have a corpus of text to analyze. The job is made harder the more acronyms or specialist terms in the data.
Source: Data Science Central
27 comments
Profile Status
ACTIVE
Profile Info


Kalyan Banga226 Posts
I am Kalyan Banga, a Post Graduate in Business Analytics from Indian Institute of Management (IIM) Calcutta, a premier management institute, ranked best B-School in Asia in FT Masters management global rankings. I have spent 14 years in field of Research & Analytics.







2 Comments
Extract and relate Human Sentiments using Text Mining - A Bayesian Learning approach - Fusion Analytics World
November 25, 2016 at 6:22 am[…] topics which reflects the reviewers’ perception about a service / product. A huge amount of text data is available through different sources across the internet where the users write reviews relating […]
Extract & relate Human Sentiments using Text Mining - A Bayesian Learning approach - Fusion Analytics World
December 7, 2016 at 6:42 am[…] topics which reflects the reviewers’ perception about a service / product. A huge amount of text data is available through different sources across the internet where the users write reviews relating […]