75 Must-Know Data Science Interview Questions

The role of a data scientist is highly malleable and company dependent. However, the general skill set needed is similar.
To prepare for your interview, you may want to brush up on these data science interview questions by reviewing some probability, data analysis, SQL, coding, and experimental design. The questions in this article should help you do so. The background of data science applicants varies wildly, so interviews may generally be more holistic and test your intuition, analytic, and communication abilities rather than focusing on specific technical concepts.
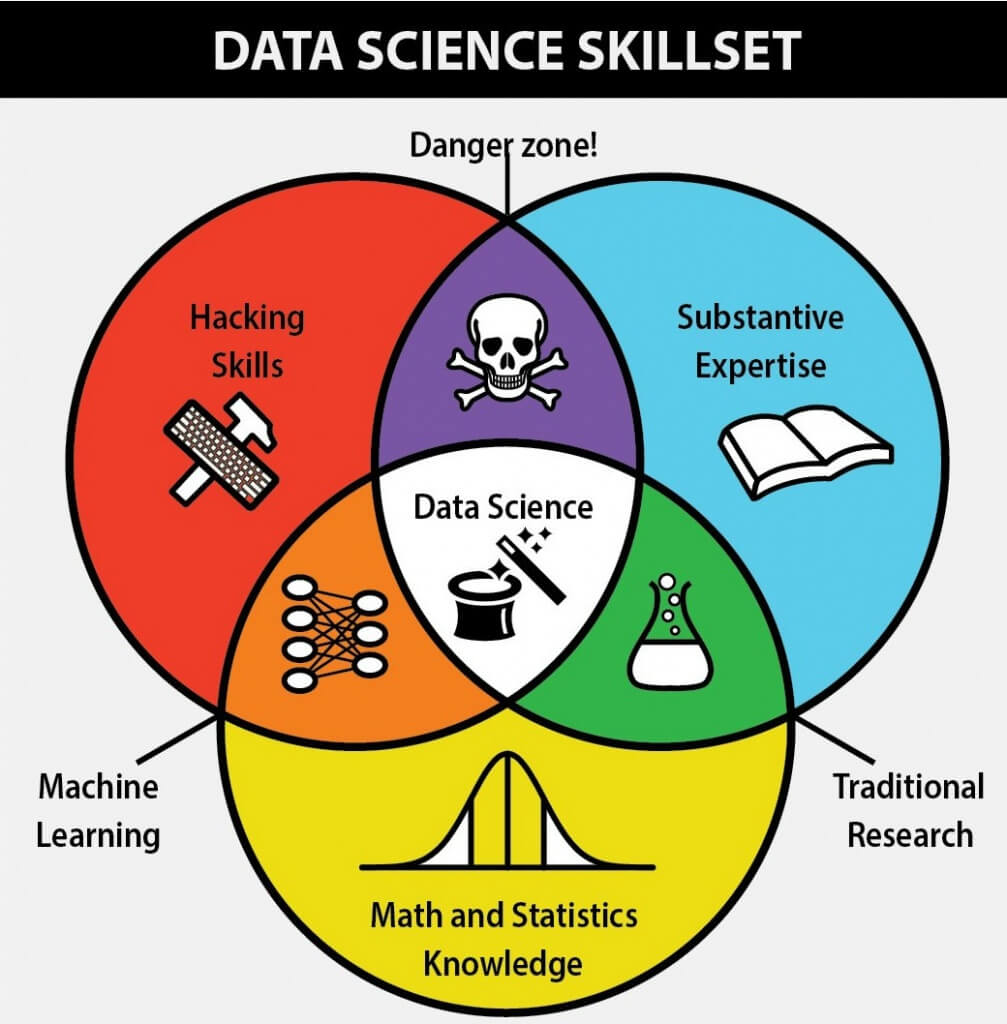
Ok, now let’s dive into the data science interview questions.
Source: Pratapactuarial
- (Given a Dataset) Analyze this dataset and give me a model that can predict this response variable.
- What could be some issues if the distribution of the test data is significantly different than the distribution of the training data?
- What are some ways I can make my model more robust to outliers?
- What are some differences you would expect in a model that minimizes squared error, versus a model that minimizes absolute error? In which cases would each error metric be appropriate?
- What error metric would you use to evaluate how good a binary classifier is? What if the classes are imbalanced? What if there are more than 2 groups?
- What are various ways to predict a binary response variable? Can you compare two of them and tell me when one would be more appropriate? What’s the difference between these? (SVM, Logistic Regression, Naive Bayes, Decision Tree, etc.)
- What is regularization and where might it be helpful? What is an example of using regularization in a model?
- Why might it be preferable to include fewer predictors over many?
- How would you construct a feed to show relevant content for a site that involves user interactions with items?
- How would you design the people you may know feature on LinkedIn or Facebook?
- Given a database of all previous alumni donations to your university, how would you predict which recent alumni are most likely to donate?
- You’re Uber and you want to design a heatmap to recommend to drivers where to wait for a passenger. How would you approach this?
- You want to run a regression to predict the probability of a flight delay, but there are flights with delays of up to 12 hours that are really messing up your model. How can you address this?
Probability
- Let’s say you have a very tall father. On average, what would you expect the height of his son to be? Taller, equal, or shorter? What if you had a very short father?
- What’s the expected number of coin flips until you get two heads in a row? What’s the expected number of coin flips until you get two tails in a row?
- Let’s say we play a game where I keep flipping a coin until I get heads. If the first time I get heads is on the nth coin, then I pay you 2n-1 dollars. How much would you pay me to play this game?
- You have two coins, one of which is fair and comes up heads with a probability 1/2, and the other which is biased and comes up heads with probability 3/4. You randomly pick coin and flip it twice, and get heads both times. What is the probability that you picked the fair coin?
- You have a 0.1% chance of picking up a coin with both heads, and a 99.9% chance that you pick up a fair coin. You flip your coin and it comes up heads 10 times. What’s the chance that you picked up the fair coin, given the information that you observed?

Source: XKCD
- In an A/B test, how can you check if assignment to the various buckets was truly random?
- What might be the benefits of running an A/A test, where you have two buckets who are exposed to the exact same product?
- What would be the hazards of letting users sneak a peek at the other bucket in an A/B test?
- What would be some issues if blogs decide to cover one of your experimental groups?
- How would you conduct an A/B test on an opt-in feature?
- How would you run an A/B test for many variants, say 20 or more?
- How would you run an A/B test if the observations are extremely right-skewed?
- I have two different experiments that both change the sign-up button to my website. I want to test them at the same time. What kinds of things should I keep in mind?
- What is a p-value? What is the difference between type-1 and type-2 error?
- What is maximum likelihood estimation? Could there be any case where it doesn’t exist?
- What’s the difference between a MAP, MOM, MLE estimator? In which cases would you want to use each?
- What is a confidence interval and how do you interpret it?
- What is unbiasedness as a property of an estimator? Is this always a desirable property when performing inference? What about in data analysis or predictive modeling?

Source: KDNuggets
- (Given a Dataset) Analyze this dataset and tell me what you can learn from it.
- What is R2? What are some other metrics that could be better than R2 and why?
- What is the curse of dimensionality?
- Is more data always better?
- What are advantages of plotting your data before performing analysis?
- How can you make sure that you don’t analyze something that ends up meaningless?
- What is the role of trial and error in data analysis ? What is the the role of making a hypothesis before diving in?
- How can you determine which features are the most important in your model?
- How do you deal with some of your predictors being missing?
- You have several variables that are positively correlated with your response, and you think combining all of the variables could give you a good prediction of your response. However, you see that in the multiple linear regression, one of the weights on the predictors is negative. What could be the issue?
- Let’s say you’re given an unfeasible amount of predictors in a predictive modeling task. What are some ways to make the prediction more feasible?
- Now you have a feasible amount of predictors, but you’re fairly sure that you don’t need all of them. How would you perform feature selection on the dataset?
- Your linear regression didn’t run and communicates that there are an infinite number of best estimates for the regression coefficients. What could be wrong?
- You run your regression on different subsets of your data, and find that in each subset, the beta value for a certain variable varies wildly. What could be the issue here?
- What is the main idea behind ensemble learning? If I had many different models that predicted the same response variable, what might I want to do to incorporate all of the models? Would you expect this to perform better than an individual model or worse?
- Given that you have wifi data in your office, how would you determine which rooms and areas are underutilized and overutilized?
- How could you use GPS data from a car to determine the quality of a driver?
- Given accelerometer, altitude, and fuel usage data from a car, how would you determine the optimum acceleration pattern to drive over hills?
- How would you quantify the influence of a Twitter user?
- Given location data of golf balls in games, how would construct a model that can advise golfers where to aim?
- How would you come up with an algorithm to detect plagiarism in online content?
- You have data on all purchases of customers at a grocery store. Describe to me how you would program an algorithm that would cluster the customers into groups. How would you determine the appropriate number of clusters to include?
- Let’s say you’re building the recommended music engine at Spotify to recommend people music based on past listening history. How would you approach this problem?
Programming

Source: Azquotes
- Write a function to calculate all possible assignment vectors of 2n users, where n users are assigned to group 0 (control), and n users are assigned to group 1 (treatment).
- Given a list of tweets, determine the top 10 most used hashtags.
- You have a stream of data coming in of size n, but you don’t know what n is ahead of time. Write an algorithm that will take a random sample of k Can you write one that takes O(k) space?
- Write an algorithm that can calculate the square root of a number.
- Given a list of numbers, can you return the outliers?
- When can parallelism make your algorithms run faster? When could it make your algorithms run slower?
- What are the different types of joins? What are the differences between them?
- Why might a join on a subquery be slow? How might you speed it up?
- Describe the difference between primary keys and foreign keys in a SQL database.
- Given a COURSES table with columns course_id and course_name, a FACULTY table with columns faculty_id and faculty_name, and a COURSE_FACULTY table with columns faculty_id and course_id, how would you return a list of faculty who teach a course given the name of a course?
- Given a IMPRESSIONS table with ad_id, click (an indicator that the ad was clicked), and date, write a SQL query that will tell me the click-through-rate of each ad by month.
- Write a query that returns the name of each department and a count of the number of employees in each:
EMPLOYEES containing: Emp_ID (Primary key) and Emp_Name
EMPLOYEE_DEPT containing: Emp_ID (Foreign key) and Dept_ID (Foreign key)
DEPTS containing: Dept_ID (Primary key) and Dept_Name
Communication
- Explain to me a technical concept related to the role that you’re interviewing for.
- Introduce me to something you’re passionate about.
- How would you explain an A/B test to an engineer with no statistics background? A linear regression?
- How would you explain a confidence interval to an engineer with no statistics background? What does 95% confidence mean?
- How would you explain to a group of senior executives why data is important?
- Tell me about a data project that you’ve done with a team. What did you add to the group?\
- Tell me about a dataset that you’ve analyzed. What techniques did you find helpful and which ones didn’t work?
- What’s your favorite algorithm? Can you explain it to me?
- How could you help the general public understanding towards the importance of using data to generate insights?
Now that you know the data science interview questions, it’s time to get cracking on some answers! So go on and study up for your interview, and don’t forget to tell us if our questions came in handy in the comments below!
Picture: Berkeleysciencereview Source: Edvancer
27 comments
Profile Status
ACTIVE
Profile Info



Kalyan Banga226 Posts
I am Kalyan Banga, a Post Graduate in Business Analytics from Indian Institute of Management (IIM) Calcutta, a premier management institute, ranked best B-School in Asia in FT Masters management global rankings. I have spent 14 years in field of Research & Analytics.








5 Comments
Exploratory Data Analysis – A Case Study - Fusion Analytics World
December 7, 2016 at 6:38 am[…] understanding, skepticism of existing assumptions – to find solutions to business challenges. Data Scientists often spend lot of time wrangling, massaging the data and building various […]
Rommel Carvalho
February 15, 2017 at 4:48 pmHi, nice compilation of questions!
I work with Data Science in the Brazilian Government and I am going to write a blog post about Data Science among other things. I was hoping you would give me permission to use your Data Science Skillset image making sure I give you credit and point to your link. Would that be possible?
Kalyan Banga
February 20, 2017 at 1:26 pmHi Rommel, Thank you for being a regular reader. Please go ahead and use the information as mentioned with due credit to Fusion Analytics World, do share the link once published. Thanks!
Nikhil
March 20, 2017 at 7:19 amHi Kalyan,
I am working with Oracle ERP for 10 years. Can you guide me to move into Data Science? Are there any certifications or what can be the entry point?
-Nikhil
The way to get a job in knowledge science - TechMintz
December 21, 2019 at 4:06 am[…] Picture credit score: fusionanalyticsworld.com […]