Making data science accessible – Logistic Regression
What is Logistic Regression?
Regression is a modelling technique for predicting the values of an outcome variable from one or more explanatory variables. Logistic Regression is a specific approach for describing a binary outcome variable (for example yes/no). Let’s assume you are own a new boutique shop. You have a list of potential clients you are thinking of inviting to a special event with the aim of maximizing the number of sales – who should you invite? Data on previous events you have run is a great starting point here, allowing you to predict an individual’s likelihood of buying given the information you have on them.
Basic Model
To start with we pick one piece of information we think may be powerful at predicting if someone will purchase at our shop (1) versus not (0): their income. Plotting the data and fitting a straight line using linear regression gives a reasonable split (below left) but the blue line (our prediction) falls outside the range 0 to 1 for a large amount of our sample. We could cap the prediction at 1 and floor at 0 (below right) – this actually gives a useful model but could we do better?

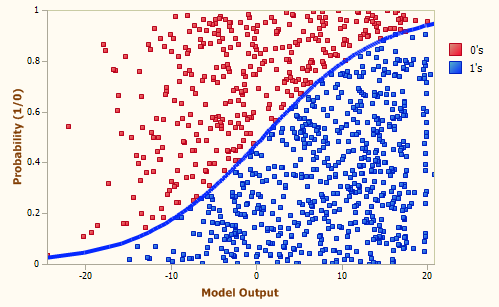
With logistic regression you are not directly predicting your 0/1 outcome – instead you are predicting the log of the odds. This allows us to fit an S-shaped relationship between our outcome and income (see below).

Variable Selection
This approach can be expanded to more than one input variable. In fact, part of the problem we have sometimes is too many input variables – in our standard model builds we can sometimes have in the region of 3,000 potential inputs. Most logistic regression packages will have some automated variable selection processes. The three most popular are:
– Forward selection starts with a model with zero input and step-by-step add the most powerful until you are not increasing predictive power with the addition of more inputs.
– Backward selection starts with a model with all your potential inputs in already and then step-by-step drop the weakest variable until you get to your final model. This is not advised if you have a large set of potential inputs.
– Stepwise selection is a combination of the two: at each step a new input is added to the model but then each existing input is tested to ensure it should stay in the model. This generally leads to more powerful models than the other approaches but can be resource-heavy.
My personal preference is to use a more manual approach. I will generally look to use a tree method (see earlier blog) to create a starting list of variables and work from there, adding or dropping variables as I feel appropriate. I feel like this allows more specialist knowledge in to the model building process.
Improving the Fit
There are other ways rather than adding more inputs for you to improve the power of your model:
– There may be interactions in your data. Below left shows an example where likelihood to spend is sloped by income band but only in the low age group. By adding the income/age interaction your model will be able to pick up this relationship. By adding the interaction term, you may boost the model’s predictive power.
– Logistic regression assumes a linear relationship between log odds and inputs – this may not be the case. Adding transformations of your data can help model fit (below center shows an example where a squared term on age may help).
Upon building your model you can get pointers for improvements by checking your residuals (observed output minus predicted). In the below right chart the model fit could be improved by adding a flag for records where income is above 60k to help bring the residuals down towards zero.

Examples where we’ve used Logistic Regression at Capital One:
Model building
Logistic Regression is our trusty, faithful tool of choice for our core risk decisioning models. The most important decision we make is deciding whether to say ‘yes’ to new customers. As such we spend a large amount of time on these models, making sure they are both predictive and understandable. We find logistic regression does a great job of balancing these two aspects: there are other more powerful machine learning models but you lose some of the clarity and intuition.
Testing new creative designs
At Capital One we run complex tests to try and find the best creatives that are most appealing for customers. We look to alter lots of different aspects of the creative making basic A/B testing inefficient. The best way to analyze these tests is through logistic regression. This allows us to identify the significant drivers as well as potential interaction terms to find the most effective.
When would I use Logistic Regression?
As with any technique related to data science Logistic Regression is one of many approaches you could take to solve a business problem using large amounts of data. The key is being able pick and choose when to take Logistic Regression off the shelf. At a high level: Logistic Regression may help you with a binary prediction problem where you want high predictive accuracy but where the model algorithm can be easily implemented and understood.
Source: Data Science Central
27 comments
Profile Status
ACTIVE
Profile Info



Kalyan Banga226 Posts
I am Kalyan Banga, a Post Graduate in Business Analytics from Indian Institute of Management (IIM) Calcutta, a premier management institute, ranked best B-School in Asia in FT Masters management global rankings. I have spent 14 years in field of Research & Analytics.








1 Comment
HR Analytics: Understanding & Controlling Employee Attrition using Predictive Modeling - Fusion Analytics World
October 11, 2016 at 2:53 pm[…] a logistic regression model using all of the independent variables to predict the dependent variable “Attrition”, […]