R Basics (stats): Data Frames
Data Frames are the tables to store data. If you recall the vectors from the first R notes data frames can be imagined as the collection of vectors with same dimension. We have already created vectors, named the vectors and plotted on histograms.
In this note we will create data frames, aggregate and plot.
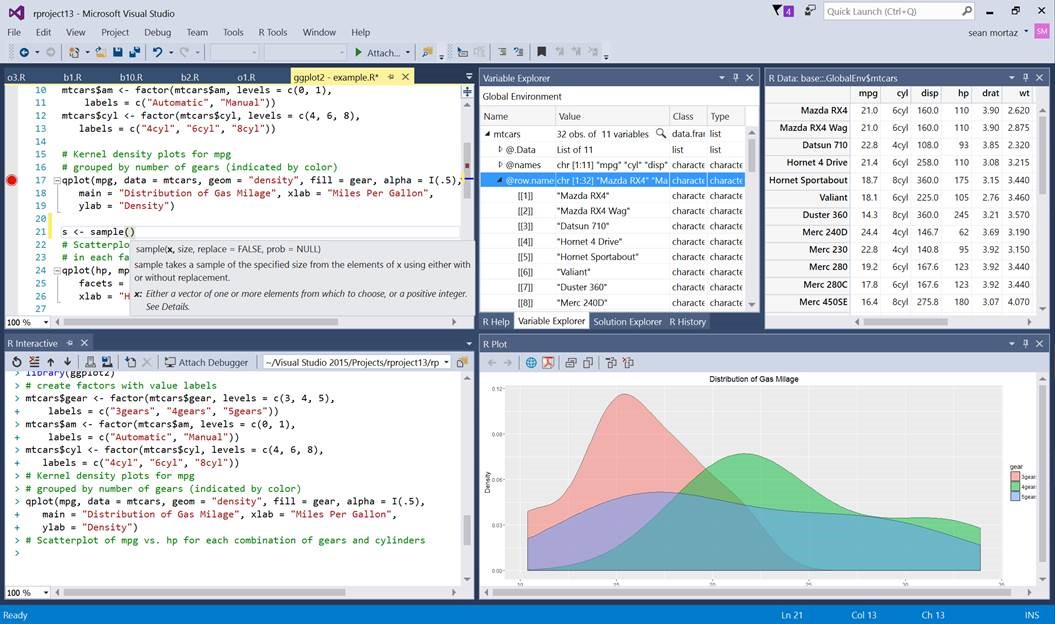
Let’s start with baby steps and create a small data frame as a new script. You can open a new script by clicking on file and new script. You can copy and paste following lines on your new script and then select the lines and run the lines as it is shown in the figure.
my_first_df<-data.frame(Customer_Id=c(“001″,”002″,”003”),
loan_type=c(“morgage”,”student loan”, “morgage”),
First_Name=c(“Jane”,”Joe”,”Sandy”),
Last_name=c(“Smith”,”Lee”,”Doe”),
Gender=c(“Female”,” “,”Female”),
Zip_code=c(“75219″,”53705″,”26789”),
amount=c(100000,50000, 15000))

Our first data frame constrained of seven vectors, Customer_Id, loan_type, First_Name, Last_name, Gender, Zip_code and amount.
NOTE: R is case sensitive. That is why I have used lower and upper case for you to practice.
After we run the lines we want to see how our first data frame looks. Following command will suffice that need:
>View(my_first_df)

We already started to have some idea about our data. We are missing the gender of Customer 002 and can learn more with a couple of commands:
class(my_first_df$Customer_Id)
class(my_first_df$loan_type)
class(my_first_df$First_Name)
class(my_first_df$amount)
str(my_first_df)
The classes might be misleading and it is important to know the type (AKA class) of the data frame. As default R treats strings in data frames as factor. Therefore, describing “stringsAsFactors=FALSE” will be an example of best practice. If you need any of the columns as factor you can define it while you are working with data. Your data frame should be created as :
my_second_df<-data.frame(Customer_Id=c(“001″,”002″,”003”),
loan_type=c(“morgage”,”student loan”, “morgage”),
First_Name=c(“Jane”,”Joe”,”Sandy”),
Last_name=c(“Smith”,”Lee”,”Doe”),
Gender=c(“Female”,””,”Female”),
Zip_code=c(“75219″,”53705″,”26789”),
amount=c(100000,50000, 15000), stringsAsFactors=FALSE)
As we already pointed out we don’t know the gender of 002 and we want to remove that record from the future aggregations. The best practice in R is to convert blank and not formatted fields to NA. So, let’s do that:
my_second_df$Gender[my_second_df$Gender==””]<-NA
View(my_second_df)
#Another way of dealing with particular column would be as follows:
#Gender_Index<-my_second_df$Gender
#Gender_Index[Gender_Index==””]<-NA
complete_df<-na.omit(my_second_df)
summary(complete_df)
str(complete_df)
Now we only have two records and we don’t have any missing field. Data entry into a data frame is as common as the missing fields and let’s see how we can enter a new record.
my_new_row<-data.frame(Customer_Id=c(“004”),
loan_type=c(“reverse morgage”),
First_Name=c(“Ted”),
Last_name=c(“Mulder”),
Gender=c(“Male”),
Zip_code=c(“75206”),
amount=c(750000), stringsAsFactors=FALSE)
my_third_df<-rbind(complete_df,my_new_row)
View(my_third_df)
HINT: View starts with capital letter; but, it is not very common for R commands. R commands usually start with lowercase letters.
HINT: Pause a moment and talk about the row numbers !! The data have row names created as a default function of R. Since we omitted the row without gender information R doesn’t know the name of the row. It assigns numbers 1,2,.. It is a good habit to remember to remove the row.names.
row.names(my_third_df)<-NULL
After we have done basic formatting we want to add a new demographics column which is date of birth (month and year) and format it as date.In order to simplify the formatting let’s assume they were all born in the first day of each month.
my_third_df$DOB<-c(“Jan 1975″,”Feb 1939″,”Jun 1990”)
View(my_third_df)
class(my_third_df$DOB)
# We want to keep the date information as date:
my_third_df$DOB<-as.Date(paste(’01’, my_third_df$DOB), format=’%d %b %Y’)
View(my_third_df)
For now you might feel very confident to create and do some simple manipulation with data frames. Let’s create a second data frame. This time I will slightly create it in a different way. You will be the judge to decide on best implementation.
my_support_df<- data.frame(Paid_amount=character(),
Customer_Id=character(),
File_No = character(),
stringsAsFactors=FALSE)
##Lets add lines of data
my_support_df[1,]<-c(5000,”001″,”1002″)
my_support_df[2,]<-c(7000,”003″,”1020″)
#Let’s add a loan date
my_support_df$Loan_Date<-c(“Feb 2010”, “Jun 2015”)
my_support_df$Loan_Date<-as.Date(paste(’01’,my_support_df$Loan_Date),format=’%d %b %Y’)
nrow(my_support_df)
length(my_support_df)
summary(my_support_df)
The support data frame and the first data frame we created share the same Customer_ID. Thus, we will be able to JOIN (merge in R) by Customer_ID.
HINT: try help(merge) and example(merge) for the further information. Merge provides features of inner and outer joins as well as cross join.
## In our case we have by.x =by.y.. So we can simply address it as by=”Customer_Id”
##Inner Join
merged_df<-merge(my_third_df,my_support_df,by=”Customer_Id”)
##Outer Join
Outer_join<-merge(x = my_third_df, y = my_support_df, by = “Customer_Id”, all = TRUE)
##Left Outer
Left_Outer_join<-merge(x = my_third_df, y = my_support_df, by = “Customer_Id”, all.x = TRUE)
##Right Outer
Right_Outer_join<-merge(x = my_third_df, y = my_support_df, by = “Customer_Id”, all.y = TRUE)
#Cross_Join
Cross_join<-merge(x = my_third_df, y = my_support_df, by=NULL)
I showed how to add names and changes of the columns and we might apply that knowledge on the data frame as well. The amount column shows the total amount of loan and it might be confusing for the future users. Let’s make it right and change the name:
names(merged_df)[names(merged_df)==”amount”]<-“Total_amount”
The support data frame included the paid amount and we may now calculate the unpaid loan amount and create a new column called Unpaind_loan.First , let’s format the Paid amount as integer. HINT: You can use other numeric formats to see how it looks and how the calculations work.
merged_df$Paid_amount<-as.integer(merged_df$Paid_amount)
merged_df$Unpaind_loan<-merged_df$Total_amount-merged_df$Paid_amount
I want to finish this part of the notes with basic visualization and using some functions to figure out which directory we are in and what directory we want to save our output file.
##Basic Visual Summary of the data
barplot((merged_df$Paid_amount),names=merged_df$File_No)
pie(merged_df$total_amount, label=merged_df$File_No)
## Setting up the directory and saving a file
getwd()
setwd(“~/Your directory”)
write.csv(merged_df,file=”merged_df.csv”)
Next notes will include some csv file reading and some more basics of aggregation. R basics are very powerful. The beauty of R and open source programs is that there is no one way of solving a problem. I know that you will have better solutions and better plots. Thank you for reading my notes and hope you feel more comfortable using R for your basic analysis.
This article taken from http://datasciencecentral.com
27 comments
Profile Status
ACTIVE
Profile Info



Kalyan Banga226 Posts
I am Kalyan Banga, a Post Graduate in Business Analytics from Indian Institute of Management (IIM) Calcutta, a premier management institute, ranked best B-School in Asia in FT Masters management global rankings. I have spent 14 years in field of Research & Analytics.









0 Comments