An Inside Update on Natural Language Processing

This article is an interview with computational linguist Jason Baldridge. It’s a good read for data scientists, researchers, software developers, and professionals working in media, consumer insights, and market intelligence. It’s for anyone who’s interested in, or needs to know about, natural language processing (NLP).
Jason and NLP go way back. As a linguistics graduate student at the University of Edinburgh, in 2000, Jason co-created the OpenNLP text-processing framework, now part of Apache. He joined the University of Texas linguistics faculty in 2005 and, a few years back, helped build a text-analytics system for social-media agencyConverseon. Jason’s Austin start-up, People Pattern, applies NLP and machine learning for social-audience insights; he co-founded the company in 2013 and serves as chief scientist. Finally, he’ll keynote on “Personality and the Science of Sharing” and teach a tutorial at the 2016 Sentiment Analysis Symposium.
In sum, Jason is an all-around cool guy, and he deserves special recognition for providing the most thorough Q&A responses I have ever received in response to an interview request. The interview? This one, covering AI, neural networks, computational linguistics, Java vs. Scala, and accuracy evaluation with a detour into Portuguese-English translation challenges, that is —
An Inside Update on Natural Language Processing
Seth Grimes> Let’s jump in the deep end. What’s the state of NLP, of natural language processing?
Jason Baldridge> There’s work to be done.
The first thing to keep in mind is that many of the most interesting NLP tasks are AI-complete. That means we are likely to need representations and architectures that recognize, capture, and learn knowledge about people and the world in order to exhibit human-level competence in these tasks. Do we need to represent word senses, predicate-argument relations, discourse models, etc? Almost certainly. An optimistic deep learning person might say “the network will learn all that,” but I’m skeptical that a generic model structure will learn all these things from the data that is available to it.
Seth> So you’re an neural-network skeptic.
Jason> No, they are a great set of tools and techniques that are providing large improvements for many tasks. But they aren’t magic and they won’t suddenly solve every problem we throw at them, out-of-the-box. When it comes to language, the only competent device we know of for processing human language fully — the human brain — is the result of hundreds of millions of years of evolution. That process has afforded it with a complex architecture that dwarfs the relative puny networks that are used for language and vision tasks today.
Humans learn language from a surprisingly small amount of data, and they go through different phases in that process, including memorization to generalization (including overgeneralization, e.g., “Mommy goed to the store”). Having said that, I love the boldness and confidence of the neural optimists, but I think we will need to figure out the architectures and the reward mechanisms by which a very deep network processes, represents, stores, and generalizes information and how it relates to language. That will imply choices about how lexicons are stored, how morphological and syntactic regularities are captured, and so on.
Is there academic computational-linguistics work that you’d call out as interesting, surfaced in NLP software tools or not?
Two items: vectorization and reinforcement learning.
The vectorization of words and phrases is one of the big overall trends these days, with the use of those vectors as the inputs for NLP tasks. The good part is that vectors are learned on large, unlabeled corpora. This injects knowledge into supervised learning tasks that have much less data.
For example, “pope,” “catholic,” and “vatican” will have similar vectors, so training examples that have just one of these words will still contribute toward better learning of shared parameters. Without this, a classifier based on bags-of-words sees these words as being as separate as “apple,” “hieroglyph,” and “bucket.” So the use of word vectors, and the fact that they can be learned with respect to a particular problem when using neural networks, has led to a standardization of sorts, of an important strategy for dealing with language inputs as continuous elements rather than as discrete, atomic symbols. The success of using convolutional neural networks for tasks like sentiment analysis concretely demonstrates the effectiveness of this strategy.
Second, reinforcement learning has been used by researchers on dialogue systems, and it’s now the new (yet, old) rage in machine learning. Witness, for example, the success of deep learning plus reinforcement learning in AlphaGo. I think it will be very interesting to see how reinforcement learning plus deep learning can be used to tackle many language tasks while reducing the number of modules and the amount of supervision needed to achieve strong performance.
With these developments plus ever faster computation and improved physical sensors, it’s fascinating and exciting times for natural language processing and for artificial intelligence more generally.
Any other thoughts to share on neural networks and AI?
The worry for someone like me is that you then get people who think deep learning method X or Y is all you need to handle NLP problems and all this interesting and possibly useful facts about language start getting swept away. Having said that, there are great papers coming out that take a neural network approach while using/building interesting representations for language. For example, Ballesteros, Dyer, and Smith’s (2015) parser, which uses character level word representations in combination with an LSTM that controls the actions of a shift-reduce dependency parser. Dyer, Kuncoro, Ballesteros, and Smith (2016) introduce Recurrent Neural Network Grammars and define parsing models for them that outperform all previous single-model parsers—and they do it with far less feature-engineering and tweaking. The DeepMind group are working on memory-based recurrent networks with stacks and queues (Grefenstette et al., 2015). This is important for working toward general neural architecture for approaching language tasks that require stacked and/or arbitrarily long dependencies (e.g. parsing).
What about to-be-done challenges in computational linguistics?
I think/hope we’ll see better computational analysis of discourse. Many models assume that the sentence is the core unit of analysis, but that’s of course a massive simplification. Consider machine translation. We’ve seen tremendous progress in the past twenty years. If you translate news articles from Portuguese to English, the results are really good. However, many things break when you move to narrative texts. For example, Portuguese is a pro-drop language that allows you to say things like “went to the beach” and leave off the subject. Consider a sequence of sentences like “A garota estava feliz. Foi a praia. Falou come seus amigos.” This sequence should translate as “The girl was happy. [She] went to the beach. [She] talked with her friends.” However, Google Translate returns “The girl was happy. Went to the beach. He talked with his friends.” Part of the reason for this is that there is a bias toward male pronouns in the English language text that the models were trained on, and when the pronoun “ela” is missing from the sentence “falou com seus amigos,” it erroneously fills the subject in the English sentence with “he.” So, we’ll likely see models coming soon that will work on both coreference and discourse structure to better translate texts like this. I actually worked on discourse structure and coreference a decade ago. We made progress, but our models were fragile and hard to integrate with each other. I’m hoping that some of the newer neural architectures can help with that.
To finish this thread: You’d say that newer technologies — machine learning and all that — have changed computational linguistics?
Certainly machine learning has changed the face of computational linguistics, over the past three decades. It starts with Bell Labs using Hidden Markov Models to recognize speech in the early 1980s; their successes there led to text-oriented NLP work incorporating machine learning starting in the late 1980s. (Philip Resnikcalls this DARPA’s shotgun wedding for NLP.)
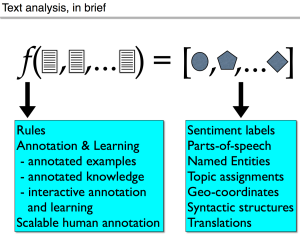
Machine learning really dominated all of NLP by the end of the 1990s. The majority of that work was using discriminative models like support vector machines and logistic regression to do text classification and generative models for language modeling and tagging. Machine learning specialists figured out that language provided fun problems and students learning in the early 2000s were trained in machine learning. So by the mid-2000s we had a larger portion of the community that could not only use machine learning methods, but also dig into their internals and tweak them. Bayesian models also became the rage in the mid-2000s. Their attraction stemmed from their support for priors, the promise of learning on less data, the natural intuitiveness of the generative stories for language problems, and the availability of inference algorithms for learning their parameters. We now see deep learning in a similar position, and it’s really leading to big improvements in important tasks like speech recognition, machine translation, parsing, and more.
The ideal scenario, from my perspective, is that new architectures will be inspired and informed by work in computational linguistics (and linguistics proper), but also that they will be learned without requiring costly and imperfect labeled data. As an example, one almost surely needs to handle syntax in some way to know that the book is the thing purchased in the sentence “I saw the book that John said Bill knows Fred bought and gave his daughter.” It would be the coolest thing ever if that could be done without needing to train a model on a treebank, but instead takes the idea of phrase-structure, dependency grammar, categorial grammar, etc, and learns the representations from pairs of sentences for machine translation. But you still need the theory/representations and a way to represent them in your network/algorithm. As another example, you might not want to be stuck with a particular word sense inventory, e.g. the one created by annotators of WordNet, but you might do well to represent the idea of word senses in your model. And so on.
You co-invented OpenNLP, now part of Apache, when you were a grad student at the University of Edinburgh, back in 2000. Back then, you were a Java proponent, but a few years back you embraced Scala.
I’m frankly not really satisfied with the JVM ecosystem as regards NLP tasks in general. OpenNLP has a solid offering, but it’s lagging with respect to the state-of-the-art. Yes, I started it as a grad student and am very happy to see its continued development, but I can no longer bear programming in Java and haven’t contributed myself in a long time.
I have contributed to ScalaNLP more recently, but I just haven’t found time to work on it in the last two years and it’s been entirely carried by David Hall. He does great work, but ScalaNLP as a whole doesn’t have the maturity and documentation necessary to be a go-to NLP framework on the JVM.
Stanford’s CoreNLP is a mature and strong system, but it doesn’t have an Apache, MIT or BSD license and that means that I and many others won’t touch it for commercial work. I’d personally love to have a JVM-based implementation along the lines of Matthew Honnibal’s SpaCy system, which is written in Python. If I had nothing else to do, I’d be happily working on an ASL-licensed NLP system written in Scala that integrates well with Spark and deep learning libraries, etc. Maybe some day I’ll be able to do that!
What other tool/environment preferences do you have nowadays, for coding NLP functions, for NLP-centered product development, and for data science?

I’m still very much Scala-centric. This has worked well for our development at People Pattern. Our data infrastructure is JVM-based, with heavy reliance on technologies like Spark and Elastic Search. It means that as we develop NLP components, we can serialize them and deploy them in both large batch analysis jobs and RESTful APIs straightforwardly. It also means that components I build are not too far from production. Overall, this has been very important for moving quickly as a small team. However, we aren’t entirely dependent on Java+Scala. For example, we use the C-basedVowpal Wabbit for much of our supervised model training. We extract and index features using Scala, output training files, estimate parameters with VW, and then read the resulting model back in to Scala and serialize the whole thing. Having said that, we are now exploring using toolkits like MLLib and H2O (for standard model types) since they integrate natively with with Spark jobs. We also have our own proprietary models, which are implemented in Scala. It’s worth mentioning that R plays a big role in our data science prototyping.
We are also working on deep learning models for image and text processing. I considered using DL4J and H2O for JVM compatibility, but I wasn’t satisfied with their current offerings for our needs and decided to opt for TensorFlow instead. TensorFlow has allowed us to quickly ramp up our efforts, and it has tremendous momentum behind it. It means we have a gap with respect to how we deploy our RESTful APIs, but our initial need is to use them for batch analysis. And, I’m still keeping an eye on DL4J and H2O.
You teamed with computational linguist Philip Resnik — you quoted him earlier — to create the ConveyAPI text analytics technology for social agency Converseon, which brought it to market via spin-out Revealed Context. Converseon has a wealth of social customer insights data and domain knowledge that you leveraged, via machine learning, to craft high-accuracy classifiers. What key lessons did you learn from the experience — general or specific to social insights — that you’d pass on to others?
There are two main lessons: the value of high quality labeled data and using diverse evaluation strategies.
Converseon amassed hundreds of thousands of annotations across tens of industry verticals. For a given text passage (e.g. comment or blog post), mentions of entities, products and terms relevant to the vertical were extracted and assigned sentiment labels, including “positive,” “negative,” “neutral,” and “mixed.” This gave us what we needed to build a sentiment classifier that used not only standard context-word and lexicon features, but furthermore features that capture the distance and relationship between the target term and the sentiment bearing phrases. For example, with a sentence like “The new Mustang is amazing, but I’m disappointed with the Camaro,” the system detects that both “Mustang” and “Camaro” are targets of interest, and it uses information like the nearness of “amazing” to “Mustang” and the fact that a discourse connective like “but” separates “disappointed” and “Mustang” (and vice versa with respect to “Camaro”). It was important to have that much high-quality labeled data to get a strong signal for these features. As a result, the model is able to say that the Mustang and the Camaro were referred to positively and negatively, respectively, in the same sentence.
How has this work proved out?
Evaluation was not done simply on overall accuracy, which is a terrible sentiment-classifier performance measure if that’s all you look at. Instead, we focused on class-specific precision and recall measures to ensure we were capturing each label well, and more importantly, to ensure that we made few positive-negative errors while being more permissive of positive-neutral and negative-neutral errors.
Humans tend to agree strongly on positive versus negative, but they disagree with each other a lot when it comes to neutral items. To get a sense of this, consider that human agreement when “neutral” is one of the labels tends to be in the 80-85% range. Because of this, we also considered the performance of our classifiers and those of other vendors with respect to average disagreement of human annotators. Across several data sets, Convey achieved 90-100% of human agreement, while other vendors were in the 80-90% range, which was a massive and pleasing discrepancy (for us).
Another important aspect of our evaluation was that we compared per-target sentiment ratios and overall ranking of products with respect to each other. The ground truth gave us counts such as 100 positive, 20 negative and 300 neutral mentions of a product like “Ford Mustang.” Given that Convey found 80 positive, 15 negative, and 250 neutral mentions, we could measure how well we captured the ground truth ratio. We furthermore measured rank correlations (e.g. Pearson’s) of all the products in a data set given ground truth sentiment ratios and our predicted ratios. Having these evaluations as part of the experimental setup used to decide development priorities and directions was important for producing a more capable classifier that generalized well to new data.
This post taken from http://breakthroughanalysis.com
27 comments
Profile Status
ACTIVE
Profile Info



Kalyan Banga226 Posts
I am Kalyan Banga, a Post Graduate in Business Analytics from Indian Institute of Management (IIM) Calcutta, a premier management institute, ranked best B-School in Asia in FT Masters management global rankings. I have spent 14 years in field of Research & Analytics.








3 Comments
Social Media Analytics - BFSI (Part II) - Fusion Analytics World
November 10, 2016 at 5:32 pm[…] Sentiment balance shows the proportionate balance of positive and negative sentiments expressed in conversations from social media. Fusion Analytics World automatically categorizes data under positive, negative and neutral sentiment using advanced text analysis and natural language processing. […]
Blueocean MI and Cross-Tab Merge to Form Course5 - Fusion Analytics World
June 7, 2018 at 3:37 pm[…] available on their smartphones and tablets. These interactive assistants, powered by advanced Natural Language Processing (NLP) and deep learning capabilities would smartly discover the insights by identifying relevant […]
ArtiE: Enterprise Platform for Voice Intelligent Solutions - Fusion Analytics World
October 26, 2018 at 1:26 am[…] not had an impact is because it was not usable. In the last few years there were advancements like NLP (Natural language processing) and NLU (Natural language understanding) and some deep learning techniques that makes voice […]